
Abstract
Introduction
L’administration américaine a récemment imposé des contrôles à l’exportation sur les grands modèles de langage les plus avancés d’Anthropic, Mythos et Fable 5. Cette décision a rappelé à tous l’urgence de la situation : l’intelligence artificielle est en train de devenir une ressource aussi importante que l’électricité ou le pétrole dans notre économie. Assurer son approvisionnement est une question stratégique décisive. Dans une économie irriguée par les grands modèles de langage (LLM), ne pas avoir accès aux meilleurs modèles, ceux qu’on appelle les modèles de frontière, c’est dépendre des autres pour une partie croissante de notre productivité, de notre puissance industrielle et de notre sécurité. Si certaines capacités des modèles franchissent un seuil (autonomie sur des tâches longues, fiabilité accrue, baisse du coût d’inférence), l’adoption peut connaître une rupture brutale. En fait, aucune question économique n’est aujourd’hui plus importante que celle-ci : serons-nous soumis au bon vouloir de puissances étrangères pour alimenter notre société en intelligence mécanique, ou serons-nous capables de la produire nous-mêmes ?
En matière d’intelligence artificielle, la France a certes de nombreux avantages, en premier lieu son parc nucléaire et l’excellence de ses chercheurs et ingénieurs. Elle dispose du seul laboratoire européen capable de produire des grands modèles de langage de taille raisonnable, Mistral. Mais il y a loin de là à disposer d'un laboratoire capable de fournir une intelligence artificielle de premier niveau, et de suivre voire mener les avancées de la frontière. En la matière, nous partons en fait presque de zéro.
Si la France et l'Europe n'ont pas réussi à faire émerger des champions aussi valables qu’Anthropic ou OpenAI, c'est pour des raisons structurelles liées à la dispersion des capitaux, à l'environnement réglementaire, et probablement à des comportements culturels. Il est difficile d'imaginer modifier rapidement ces paramètres : l’unification du marché des capitaux européens est un serpent de mer, la simplification du droit national et européen aussi. On peut dire sans risque de se tromper qu’un laboratoire d’intelligence artificielle de pointe ne s’y développera pas de manière organique. Toute volonté politique de remettre la France dans la course à l’intelligence artificielle ne pourra donc passer que par un effort délibéré de l’Etat.
Mais de quel effort parle-t-on, et de quelle ampleur ? La plupart de ceux qui appellent aujourd’hui à une intelligence artificielle souveraine le font sans en mesurer le prix. Or l’équation politique varie du tout au tout selon l’ordre de grandeur. Est-il équivalent au coût d’un nouveau porte-avion, par exemple ? S’agit-il plutôt d’un effort comparable au plan Messmer, qui a mobilisé pendant un temps plus d’1% du PIB français pour bâtir la flotte de réacteurs nucléaires qui sont encore notre assise énergétique ? Cela va-t-il plus loin encore ?
C’est l’objet de cette note : calculer les montants à investir pour créer et maintenir un laboratoire de frontière en France, et déterminer par quels moyens y parvenir, avant d’en tirer les conclusions stratégiques qui s’imposent.
Créer un laboratoire de frontière
Qu’est-ce qu’un laboratoire de frontière ?
Le terme de “frontière”, en IA, désigne davantage une dynamique qui se déploie dans le temps que la performance d'un modèle à un instant donné : la durée, mesurée en temps humain expert, des tâches qu’un agent peut réussir avec un certain niveau de fiabilité a doublé environ tous les 7 mois. La plupart des benchmarks, rapidement saturés, deviennent moins des instruments de mesure fine des performances des modèles que des conditions minimales d’entrée à la frontière. L’accès à la frontière ne peut pas être pensé comme l’achat ponctuel d’un modèle. Il suppose une capacité durable à suivre et absorber la dynamique. A la frontière, les capacités de calcul nécessaire à l'entraînement d’un modèle doublent tous les 5,2 mois depuis 2020. Sur la même période, le coût d’entraînement des modèles de frontière double tous les 7 mois. Les gains d’efficacité matérielle et algorithmique sont également rapides mais ne compensent pas la montée de l’ambition : ils permettent surtout de viser des modèles plus capables, plus longs à entraîner, plus agentiques et plus intensifs en inférence.
Les laboratoires à la frontière de l’IA reposent sur la maîtrise d’un ensemble intégré de ressources pour financer les itérations suivantes de développement des modèles, et assurer leur déploiement à grande échelle. Leur avantage tient autant à la qualité scientifique des équipes techniques qu’à l’accès continu au capital, aux données, et aux infrastructures de calcul nécessaires pour repousser la frontière. De plus en plus, ils reposent en outre sur l’accès aux modèles d’IA eux-mêmes, qui assistent les développeurs dans la production des futurs modèles, voire mènent leurs propres expérimentations pour accélérer automatiquement la R&D ; c’est le processus qu’on nomme recursive self-improvement, et qui pourrait conduire à un accroissement rapide de l’écart entre les laboratoires bénéficiant des meilleurs modèles (les leurs) et leurs concurrents.
Le calcul, nerf de la guerre
Le principe fondamental de l’IA aujourd’hui, et l’unique raison pour laquelle les entreprises d’IA se lancent dans une course démesurée aux investissements, s’appelle les lois d’échelle. Il s’agit de lois empiriques selon lesquelles l’intelligence du modèle croît linéairement en fonction du logarithme de la puissance de calcul employée, que ce soit dans l’entraînement du modèle ou plus tard à l’utilisation.
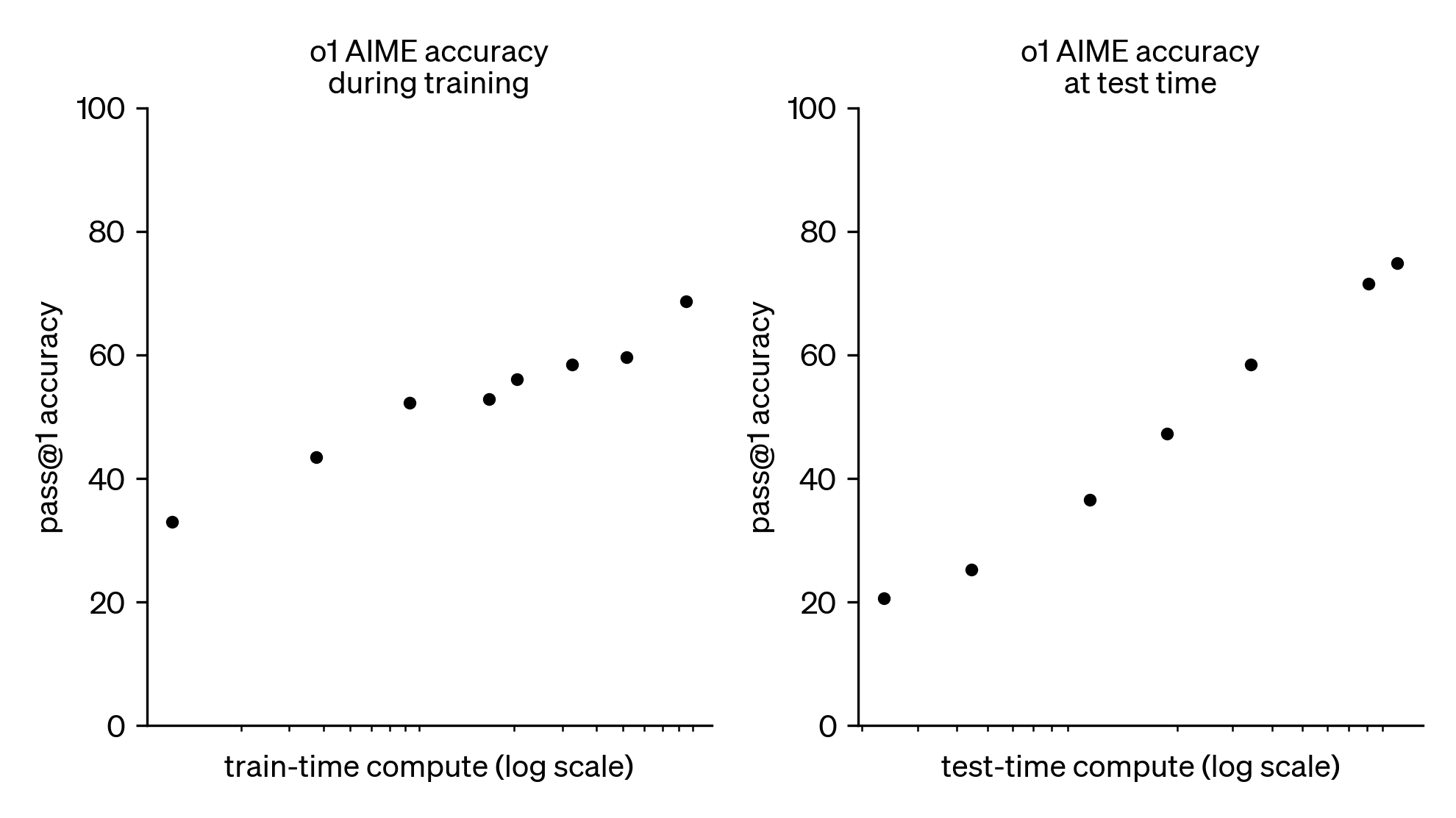
Les lois d’échelle - Graphe publié par OpenAI dans le rapport technique de leur modèle o1 en décembre 2024
Certes, cette formule se fait de plus en plus coûteuse à mesure qu’on démultiplie la puissance investie, mais la promesse est fabuleuse : atteindre une intelligence illimitée, plus vaste que celle de nos plus grands polymathes, capable de contribuer au progrès scientifique et technique davantage que tous nos prix Nobel. Bien sûr, rien ne garantit que ces lois continuent de tenir à long terme. Mais elles tiennent jusqu’ici, ce qui suggère d’ailleurs que l’intelligence est une affaire de quantité. C’est cette promesse qui rend l’investissement si important : l’IA devenant une entité supérieurement intelligente capable de faire des bonds de géant dans tous les domaines scientifiques et techniques, donc aussi dans les armements, la souveraineté d’un Etat ne pourra se maintenir sans maîtrise de l’IA.
Gagner la course est donc principalement affaire de calcul, ce que confirme l’état actuel de la course mondiale. Les deux laboratoires aujourd’hui à la frontière, Anthropic et OpenAI, sont aussi ceux qui disposent de la plus importante réserve de puissance de calcul (compute). On la mesure aujourd’hui le plus souvent en énergie utilisée : chacun de ces laboratoires contrôle aujourd’hui l’équivalent de plusieurs GW. Et c’est bien la puissance de calcul qui fait la différence :
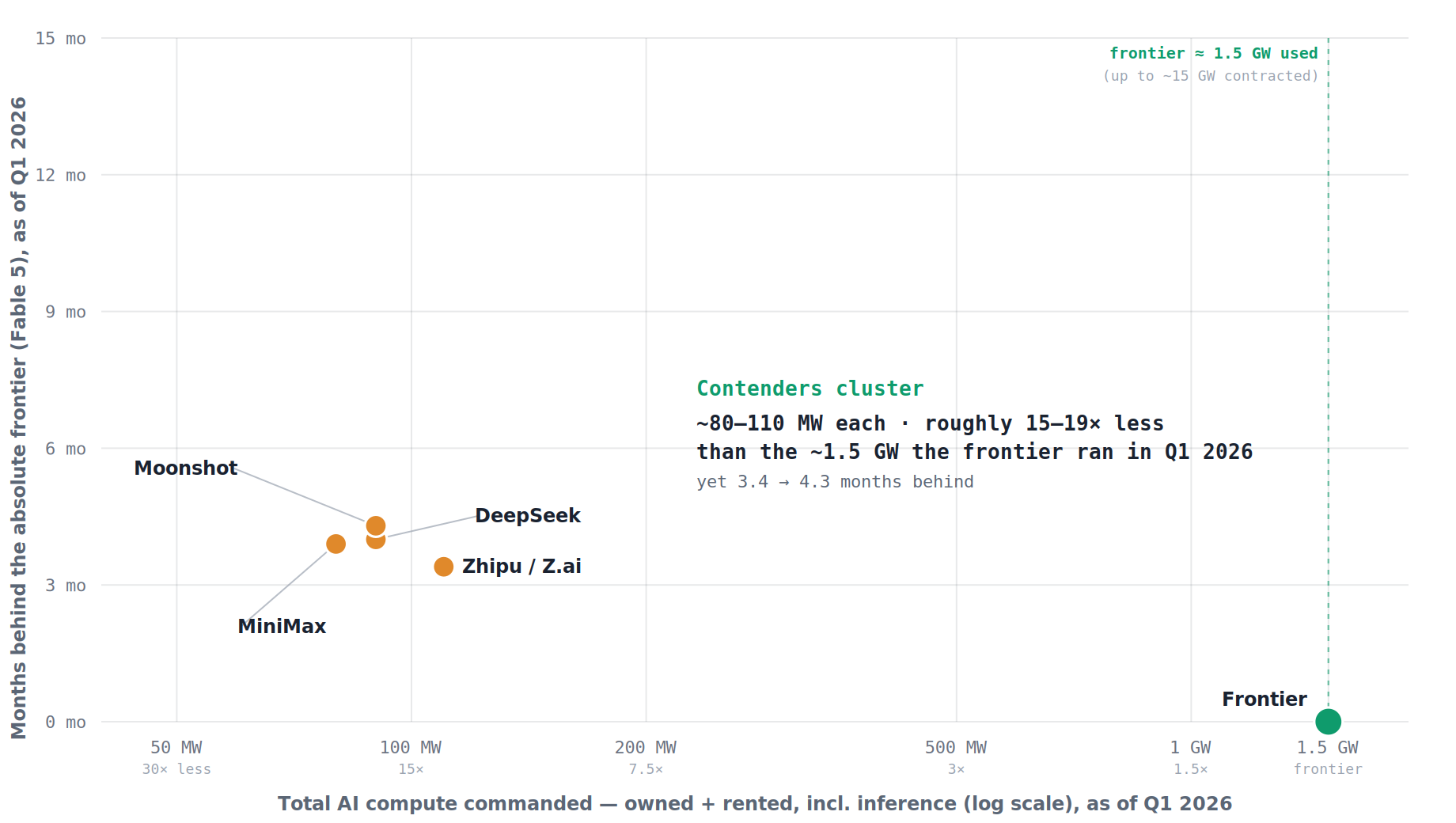
La mesure de performance repose ici sur l’indice d’Artificial Analysis qui est un indicateur utile, quoique très incomplet, de la frontière. L’écart réel entre Fable 5 et les laboratoires chinois est certainement supérieur à l’écart d’environ 4 mois ici observé. D'abord l’indice sature par le haut: il compresse les écarts entre les meilleurs modèles. Cette compression peut donner l’impression d’un retard modéré, alors même que les différences restent beaucoup plus nettes sur les tâches les plus difficiles (sur ARC-AGI-2, par exemple, les modèles chinois ont encore ~8 mois de retard). D’autre part, une moyenne agrégée masque la forme réelle de la frontière. Avoir « quatre mois de retard » ne dit pas quelles capacités restent inaccessibles aujourd’hui, ni quelles classes de tâches ne sont débloquées que par le meilleur modèle disponible. A la frontière, l'avance n'est pas linéaire mais cumulative: le meilleur modèle sert à entraîner, distiller et accélérer le suivant, capte les usages les plus rentables et les meilleurs talents, et fixe le standard que les autres rattrapent.
Au vu des performances de modèles développés par des “pure players” chinois, aux ressources en principe plus limitées que les grands laboratoires américains, certains jugent aujourd’hui qu’il est possible d’entraîner des modèles de frontière avec une puissance de calcul, et donc un coût, beaucoup moins important que la norme américaine. GLM 5.2, publié le 16 juin 2026 par Zhipu, rivalise avec Claude Opus 4.8, sur certains benchmarks, alors que Zhipu ne disposerait que d’une fraction des capacités de calcul d’Anthropic (qui plus est sous forme d’allocation et non d’un compute à leur main). Mais d’une part, les véritables capacités financières et de calcul des firmes chinoises sont difficiles à évaluer. D’autre part, il est clair qu’une partie des performances de leurs modèles vient de la distillation des modèles commerciaux américains , c’est-à-dire de l’usage de ces modèles pour générer des données et environnements d’entraînement. Prendre l’exemple d’un Deepseek ou d’un Zhipu pour en tirer la conclusion qu’il est possible d’avoir en Europe un laboratoire de frontière à bas coût serait une erreur. En un sens, la distillation est un accès à de la puissance de calcul par procuration, où le coût de la frontière a d’abord été payé ailleurs. Enfin, un modèle comme GLM 5.2 n’est pas à la hauteur des modèles d’Anthropic et OpenAI sur d’autres séries de benchmarks, et semble globalement moins versatile et performant.
Il est vrai aussi qu’une large partie du compute disponible chez OpenAI et Anthropic est destinée à l’inférence, c’est-à-dire à l’usage des modèles par les utilisateurs, et non à l’entraînement de ces modèles. En soi, il pourrait être tentant de penser que l’entraînement est possible avec beaucoup moins de puissance de calcul, mais là encore, le raisonnement serait fallacieux, puisque c’est notamment les données résultant de l’usage massif de leurs modèles par les utilisateurs qui facilitent l’entraînement des modèles suivants. Il faut donc distinguer training et inférence sur le plan de l’architecture, mais non les opposer sur le plan stratégique. Pour un laboratoire à la frontière, le calcul forme un portefeuille stratégique à arbitrer entre entraînement, R&D, inférence interne (RL, données synthétiques, automatisation de la recherche), inférence client. Les effets d’échelle jouent sur chacun de ces maillons : plus un laboratoire sert d’utilisateurs, plus il apprend à réduire son coût par token, à améliorer ses kernels, son routage, son batching ou le taux d'utilisation des accélérateurs; plus son inférence devient efficace, plus il peut vendre d’intelligence, générer de revenus, capter des données et des signaux d’usage et réinvestir dans le cycle suivant. Enfin, l’inférence permet elle permet aussi le test-time scaling, c’est-à-dire l’amélioration des performances par davantage de calcul au moment de la résolution des tâches (voir le graphe Les lois d’échelle au-dessus). L’inférence est donc un moteur économique et technique essentiel de la frontière.
Nous en concluons que, si la France souhaite disposer de son propre laboratoire capable de la fournir en IA de frontière sur le moyen et long terme, il faut une organisation dont l’ampleur et les moyens soient proches des grands laboratoires américains.
Quel serait le prix d’un tel projet ?
Par simplicité, faisons abstraction à ce stade des véhicules existants capables d’héberger et de conduire ce projet, et raisonnons par les premiers principes : combien de GPU, d’énergie et de chercheurs faudrait-il pour créer ce laboratoire ?
Puissance de calcul
Fin 2025, OpenAI disposait d'environ 1,9 GW et Anthropic de 1,4 GW ; les deux laboratoires sont attendus autour de 5 à 6 GW chacun dès fin 2026, et OpenAI projette une capacité de l'ordre de 12 GW en 2027. Nous proposons de retenir pour objectif un dimensionnement de l'ordre de 5,5 GW de charge IT, soit environ trois millions de GPU de classe Blackwell. Cela équivaut à rejoindre le niveau actuel des acteurs à la frontière, ce qui est donc loin d’être une ambition maximaliste. Ce volume se compare d'ailleurs à la moitié du programme Stargate (500 Md$ pour 10 GW) et à la moitié des quelques 10 GW qu'Anthropic a réservés en quelques semaines de 2026 auprès d'Amazon, de Google et de Broadcom.
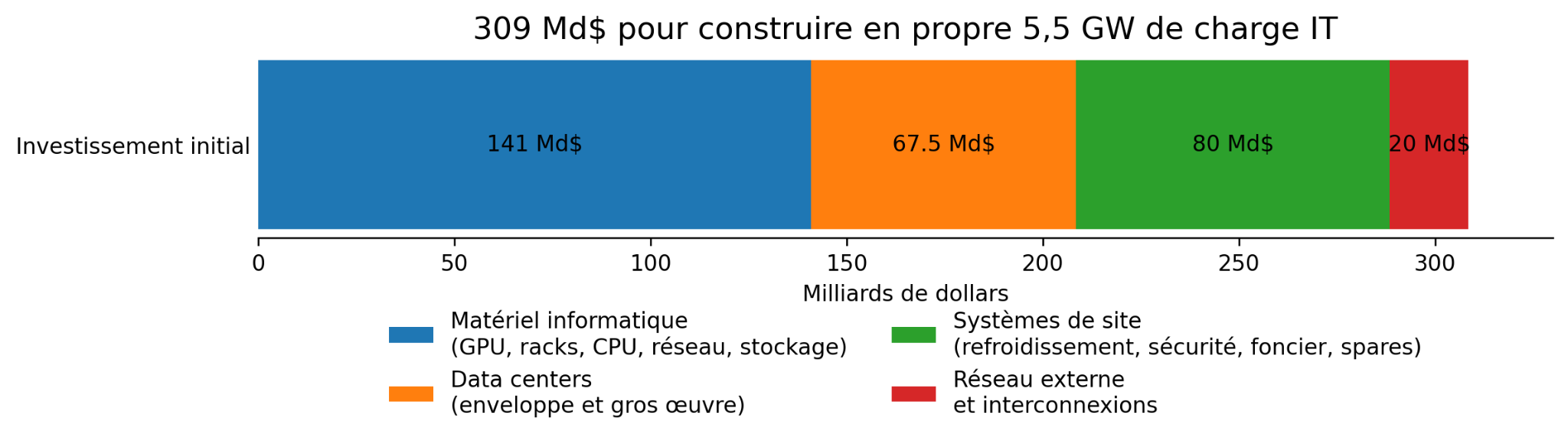
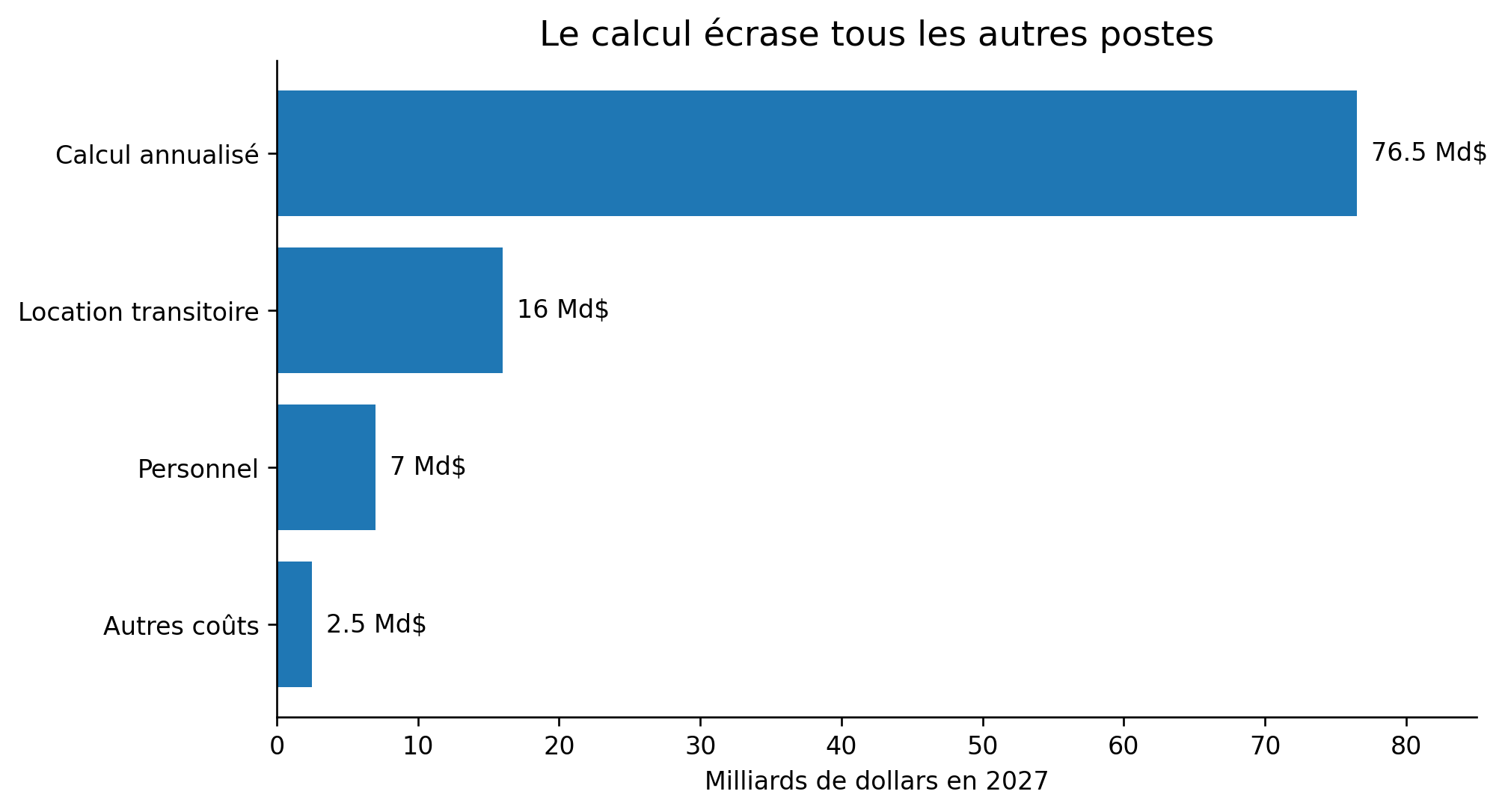
Le premier coût est l’investissement industriel nécessaire pour disposer en propre de cette capacité de calcul. Il est de l’ordre de 300 Md$ sur 4 ans et comprend l’ensemble de l’actif à construire : environ 141 Md$ pour le matériel informatique (GPU, racks, CPU, réseau interne, interconnexion et stockage), 67,5 Md$ pour l’enveloppe et le gros œuvre des data centers, 80 Md$ pour les systèmes de site (refroidissement, sécurité, foncier, pièces de rechange, intégration), et 20 Md$ pour le réseau externe et les interconnexions. Annualisé, ce bloc de calcul représente environ 75 Md$ en 2027, en incluant l’amortissement du matériel, le coût du capital, l’entretien des data centers, les systèmes de site, le réseau et l’électricité. Cela représenterait une consommation d'environ 53 TWh par an (soit déjà 10% de la consommation électrique annuelle française) et une facture électrique de l'ordre de 4 Md$ par an sur une hypothèse de prix moyen de l’électricité française de 77 dollars/MWh.
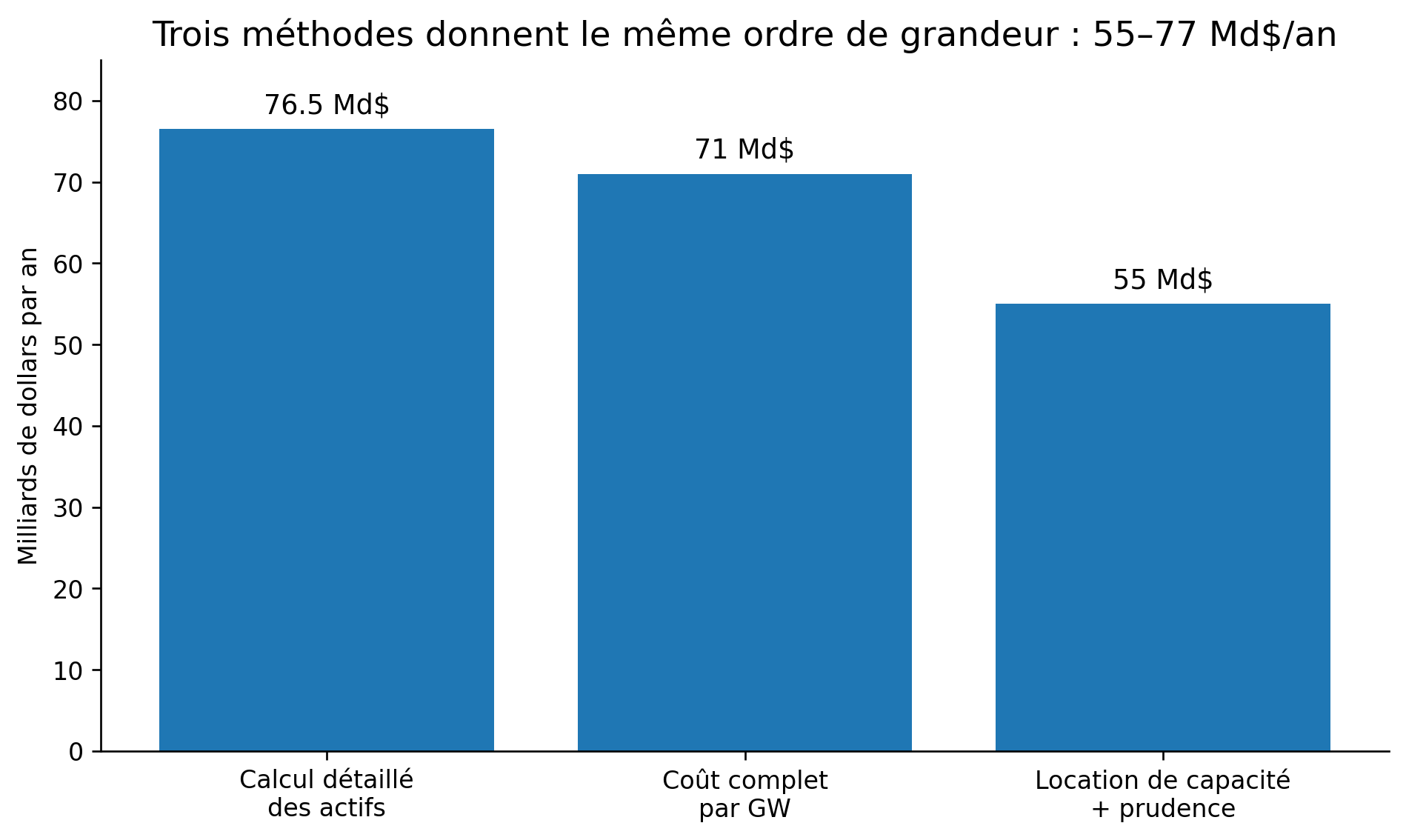
Cette estimation par les premiers principes est confortée si on la compare au coût des mégaprojets existants comme Stargate, ou aux loyers payés par Anthropic pour accéder au calcul disponible de SpaceX : selon la méthode utilisée, nous aboutissons à une fourchette de 55 à 75 Md$ par an.
Recrutement
La puissance de calcul est une base indispensable, mais elle ne suffit pas à atteindre la frontière ; les échecs (à date) de Meta et xAI pour rivaliser avec Anthropic et OpenAI, en dépit de capacités importantes, de l’ordre respectivement de 4 et 1,5 GW, montrent l’importance de la qualité des chercheurs et de la culture du laboratoire.
Si l’on vante souvent, à raison, les compétences des chercheurs et ingénieurs français, l’Europe manque cependant d’expérience et donc d’expertise dans l’entraînement actuel des modèles de frontière. Si l’on veut y prétendre, il faut payer le prix pour attirer les chercheurs des grands laboratoires américains (ce qui, dans certains cas, consistera d’ailleurs à faire revenir des talents européens).
Il n’y a pas besoin d’un nombre énorme d’employés : nous retenons une équipe resserrée d’environ 1700 personnes, Anthropic ayant 3000 employés et OpenAI 5000 (avec des dimensions de produit et de marketing que nous laissons pour l’instant au second plan). Il s'agit d'une cible de régime permanent, atteinte progressivement sur 24 à 30 mois. En revanche, les rémunérations sont élevées, surtout au sommet : il est indispensable de mobiliser une cinquantaine de chercheurs d’élite, venus des meilleurs concurrents, pour lesquels nous comptons 3 Md$ de rémunération annuelle : 100 M$ par fondateur (même si cela pourrait prendre la forme de participations) et 45 M$ par chercheur de classe mondiale. C’est le prix de marché : les rémunérations à neuf chiffres sont devenues ordinaires pour les débauchages entre laboratoires. Notons au passage, même si nous nous concentrons ici sur les moyens financiers, que l’argent ne suffit pas : les difficultés rencontrées par xAI montrent qu’au-delà du niveau de rémunération, la capacité à attirer durablement les meilleurs chercheurs dépend aussi de la culture scientifique ou de la gouvernance.
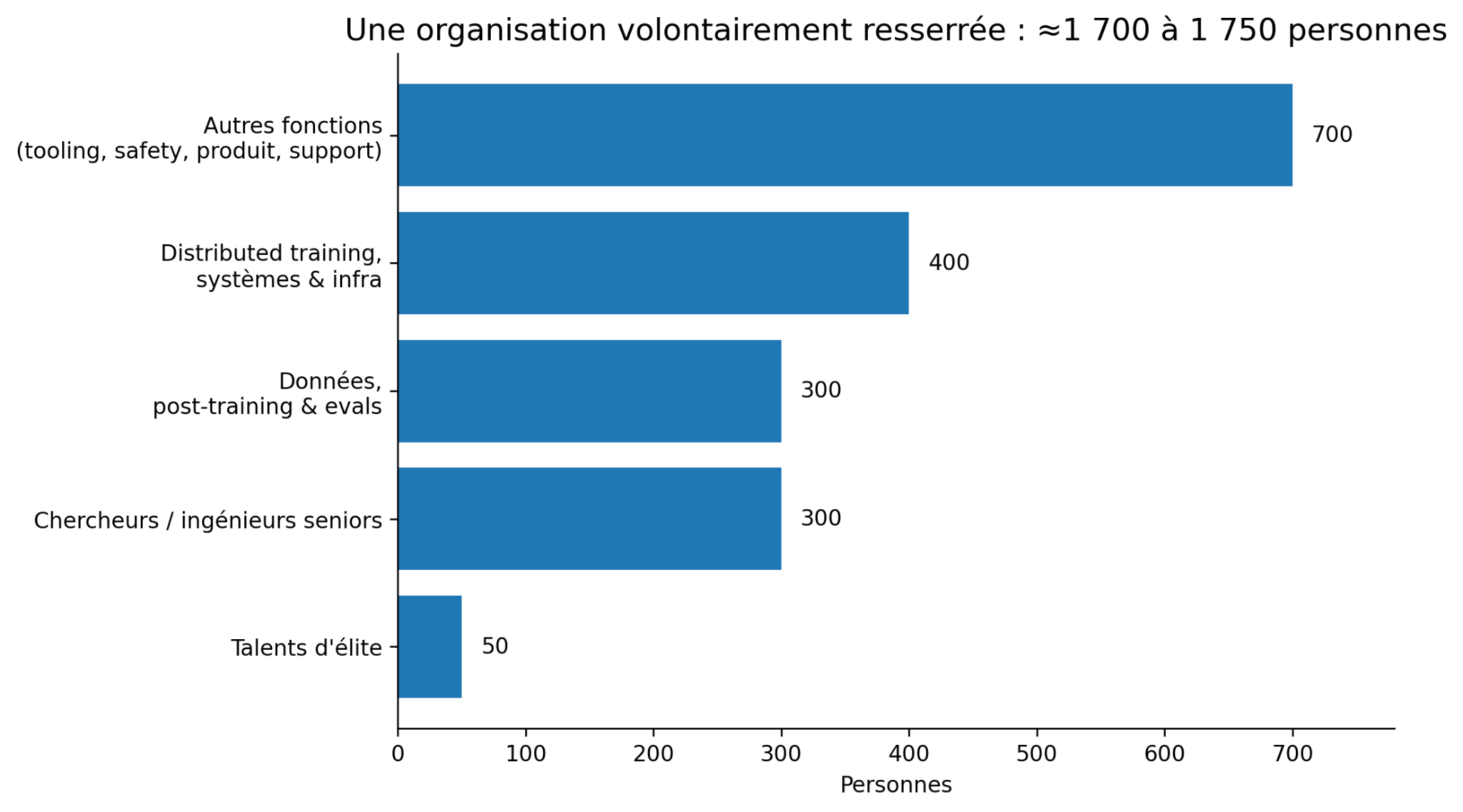
La base de l'organisation rassemble à titre indicatif 300 chercheurs et ingénieurs seniors (autour de 4 M$ chacun), 400 spécialistes de l’entraînement distribué, des systèmes et de l'infrastructure ainsi que 300 personnes dédiées aux données, au post-training et aux évaluations (environ 2 M$ chacun), auxquels s'ajoutent 150 personnes sur le tooling de R&D, 150 sur la sécurité et la cyberdéfense, 250 sur le produit et 150 sur les fonctions juridiques, RP, RH et support.
Au total, la masse salariale s'établit autour de 7 Md$ par an, soit un dixième seulement (et malgré la hauteur des salaires) du coût annualisé du calcul. Les talents sont moins coûteux que les GPU, ce qui justifie d’autant plus de les payer extrêmement bien.
Maintien à la frontière
Pour tenir compte de l’évolution rapide de la frontière, il faut ensuite calculer la trajectoire des coûts sur plusieurs années, après la phase de construction.
Nous retenons des rythmes de croissance annuelle différenciés selon les postes. Le calcul, principal moteur de la performance, croît de 30 % par an pour suivre l'effort des concurrents et absorber les nouvelles générations de matériel ; c’est déjà une hypothèse très conservatrice, si l’on rappelle les phénomènes de croissance mentionnés plus haut. La masse salariale progresse plus modérément, autour de 15 % par an : l'équipe reste resserrée, mais les rémunérations continuent de grimper sous l'effet de la concurrence. Les autres coûts du laboratoire augmentent de 10 % par an. Nous modélisons en outre le prix d’une location de compute transitoire dans les premiers temps du laboratoire (16 Md$ puis 4 Md$ les deux premières années), qui s’éteint progressivement à mesure que les centres de données dédiés entrent en ligne, afin de permettre aux chercheurs de commencer à travailler le plus tôt possible.
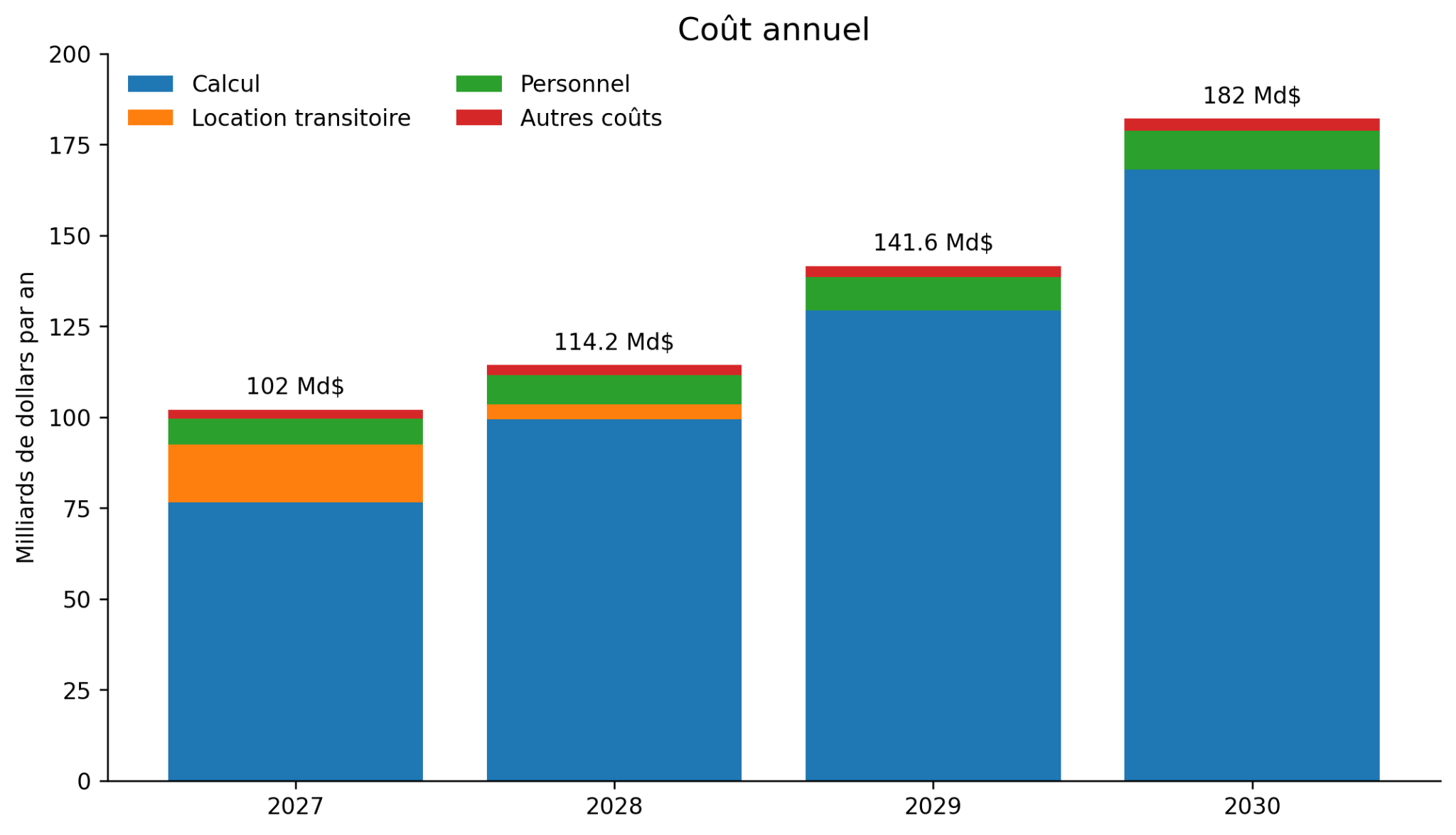
Sur cette base, le coût annuel total s’établit à 102 Md$ en 2027 et s’élève jusqu’à 182 Md$ en 2030, ce qui représente un cumul de l'ordre de 540 Md$ sur quatre ans. Le calcul en représente l'écrasante majorité : à lui seul, il pèse environ 470 Md$ cumulés.
L’investissement est donc plus que massif : environ 3 à 5% du PIB français par an.
Bénéfices financiers
Avant même d’évoquer la valeur économique, politique et stratégique d'un tel projet, il faut rappeler qu'un laboratoire de frontière est aussi un actif productif. L'effort consenti n'est pas à perte : il peut engendrer des revenus s'il réussit, et conserver une valeur substantielle même s'il échoue.
La majeure partie du compute des grands laboratoires est destinée à l'inférence, qui se monétise par l'accès facturé à l'API (au token), par les abonnements grand public et entreprises, et de plus en plus par des produits agentiques qui automatisent des pans entiers du travail intellectuel. Les revenus des laboratoires de tête croissent à des rythmes de doublement annuel ou davantage, pour atteindre plusieurs dizaines de milliards de dollars par an. Un laboratoire français disposerait en outre d'un avantage structurel, un marché souverain en partie captif. À terme, une fraction des coûts annuels pourrait ainsi être autofinancée par les recettes.
Par ailleurs, même si le laboratoire échouait à rejoindre la frontière, la France resterait propriétaire de 5,5 GW de data centers. Ce sont des actifs durables et précieux. Ce compute pourrait être loué (inférence à la demande, cloud souverain), mis au service de l'écosystème européen de recherche et de startups, ou redéployé vers d'autres charges intensives. Notons toutefois que les GPU eux-mêmes se déprécient brutalement, avec une durée de vie utile de quelques années seulement, ce qui justifie l'amortissement intégré à notre modèle. Le socle patrimonial réside surtout dans l'enveloppe, l'énergie et le foncier. Mais ce n'est pas la part la moins difficile à obtenir ni la moins valorisable.
Alternatives stratégiques
Un coût aussi massif peut décourager les responsables politiques français et européens, qui se jugeraient incapables de le financer. Dans ce cas, quelles autres voies pourraient être suivies ?
La première est un pari sur l’open source : jusqu’ici les modèles ouverts ont suivi de quelques mois les performances des modèles commerciaux, et l’économie européenne peut donc, en dernier ressort, recourir aux premiers pour assurer son alimentation en intelligence artificielle, sans dépendre de quiconque. Le pari est risqué et, au demeurant, implique un coût non négligeable. Pour faire tourner ces modèles, il faut l’énergie et les infrastructures suffisantes, ce qui implique en soi d’énormes investissements. Surtout, rien ne garantit que le flux de modèles ouverts ne se tarira pas. Leurs développeurs, aujourd’hui principalement chinois, peuvent soudainement décider de les rendre commerciaux. Dans ce cas, l’Europe se trouverait tout aussi dépendante de la Chine que des Etats-Unis. Ces modèles pourraient aussi subir les mêmes restrictions d'accès que les modèles américains fermés par exemple au-delà d’un seuil de capacité de type « Mythos ». Si ces modèles venaient à rattraper la frontière, ils pourraient être qualifiés de risques pour la chaîne d’approvisionnement (supply-chain risk) par l’administration américaine, entraînant des restrictions, voire des interdictions, sur leur achat, leur utilisation ou leur hébergement par les entreprises américaines. Par effet d’extraterritorialité, de conformité ou de pression réglementaire, leur adoption deviendrait également plus difficile pour les entreprises européennes.
La deuxième voie envisageable est celle d’une dépendance négociée envers les Américains. Les Etats-Unis construisent des modèles et l’Europe les utilise. Pour éviter une soumission totale, certains font valoir que l’Europe a des leviers dans la chaîne de valeur qu’elle peut utiliser à son tour pour faire pression sur les Etats-Unis ; en d’autres termes, la souveraineté devrait se trouver dans la dépendance mutuelle plutôt que dans l’indépendance. Il est vrai que les chaînes de production sont dispersées à travers le monde et que personne ne maîtrise unilatéralement l’intégralité des composants nécessaires au développement et à la diffusion de grands modèles de langage. Mais il ne faut pas se faire d’illusions : la principale brique que maîtrisent les Européens, celle de la production des machines de photolithographie pour l'industrie des semi-conducteurs (à travers ASML), n’est pas un levier si efficace dans une négociation. C’est un maillon indispensable de la chaîne, mais avec une forte latence : si l’Europe bloquait les exportations d’ASML, non seulement elle asphyxierait cette société, mais les effets de ce blocage ne se feraient sentir qu’après de nombreux mois, puisque les autres acteurs pourraient utiliser leurs stocks existants. A l’inverse, bloquer un modèle de frontière est instantané pour les Etats-Unis, comme l’exemple de Fable 5 l’a montré. L’arme ASML peut éventuellement servir dans un bras-de-fer focalisé sur l’infrastructure, comme on l’a dit plus haut, mais elle est moins efficace s’agissant du produit final. Dans un monde où l’économie européenne repose intégralement sur l’usage de modèles américains, l’Union européenne pourrait-elle se permettre de passer seulement quelques jours sans eux ? Rien n’est moins sûr.
Au mieux, les Etats européens peuvent essayer de pallier ce désavantage en contraignant l’accès des fournisseurs américains au marché européen à la présence physique des modèles sur des centres de données situés en Europe et juridiquement maîtrisés par eux. La Corée du Sud a par exemple formalisé un partenariat entre Shinsegae, conglomérat national, prenant en charge l’infrastructure physique et la startup américaine Reflection AI apportant les modèles open weights et l’ingénierie pour bâtir un site de 250 MW, présenté comme une grande “AI factory” souveraine destinée aux entreprises et administrations coréennes. Cela éviterait de donner aux Etats-Unis un “kill switch” instantané, comme ils l’ont aujourd’hui ; mais cela n’empêcherait pas Washington de décider, à loisir, d’arrêter le déploiement de futurs modèles en Europe. Au surplus, l’Union européenne n’a pas fait la preuve de sa capacité à se coordonner pour répondre unanimement et vigoureusement à des pressions de ce type, puisque sa structure invite aux comportements de passager clandestin.
Peut-on, enfin, espérer jouer de la rivalité entre Etats-Unis et Chine pour ne dépendre ni de l’un ni de l’autre en les mettant en concurrence ? Ce serait un jeu risqué : les Etats-Unis seraient bien conscients qu’une Europe les menaçant de passer aux modèles chinois se mettrait immédiatement dans la main de la Chine, et inversement, de sorte que nous aurions peu de marge de négociation.
Peut-être ces solutions seront-elles celles que la France et l’Europe adopteront. Dans ce cas, il faudra au moins cesser de se prévaloir du concept de souveraineté et d’indépendance européenne, et admettre qu’il s’agira de gérer au mieux notre dépendance. Beaucoup de pays européens y sont déjà habitués en ce qui concerne leur approvisionnement énergétique, et ce sera donc pour eux la pente naturelle.
Conclusion
De Gaulle rapporte ainsi la réaction de Khrouchtchev en 1960 quand, à Rambouillet, il lui apprend le succès de la bombe atomique française : « Je comprends votre joie. (...) Mais, vous savez, c'est très cher. » Il commente : « Mon récit n'a provoqué aucune réaction de la part de mes interlocuteurs, sauf celle-ci : “Ah oui ! C'est très cher !” “C'est très cher”, même pour les Américains, même pour les Russes. (...) Mais pour nous, face à ces visées impériales, c'est le prix de l'indépendance. »
**
Comment le construire ?
Vu l’énormité des moyens à consacrer au projet, l’architecture retenue pour le mettre en œuvre est décisive. Comment organiser les ressources investies dans cet effort herculéen ? Faut-il mettre en concurrence plusieurs entreprises ? Ou concentrer les moyens dans une seule, et si oui, laquelle ? Et quel rôle doit-y jouer l’Etat ?
Véhicule
S’il s’agissait de réduire à une équation la performance des modèle sortis d’un laboratoire, on pourrait écrire, à partir des observations faites plus haut :
performance = compute × data × organisation × cerveaux
OpenAI, Anthropic, Meta ou xAI sont notablement en avance sur le compute. Le facteur d’organisation est peut être le réactif limitant chez d’autres entreprises, comme la hiérarchie trop pesante chez Meta et dans une moindre mesure chez Google, ou la direction de Musk chez xAI. Au contraire, les entreprises chinoises plus limitées par le compute se défendent sur le facteur des cerveaux, avec des chercheurs brillants et une ingénierie de première classe.
Mais une fois cette équation posée, comment maximiser le produit ? Faut-il investir dans un champion, ou plusieurs? Il existe naturellement une tension entre la concurrence et la concentration des moyens. Aux Etats-Unis, la concurrence a laissé émerger des acteurs multiples qui ont tous joué leur part dans le progrès du pays : c’est Google qui a découvert Transformers, OpenAI qui a découvert les scaling laws sur l’inférence avec o1, Anthropic qui a publié les agents de code ouvrant un chemin vers le self-improvement. L’exemple chinois est d’ailleurs singulier : le gouvernement entretient une flotte de datacenters qui monte progressivement en puissance. Les neo-labs comme Zhipu, Moonshot, ou MiniMax sont ensuite en compétition pour obtenir des grants, des autorisations d’utilisations à durée limitée ; l’obtention d’un grant est bien sûr conditionnée à la puissance passée, ce qui permet de laisser jouer la concurrence pour faire émerger de nouvelles idées, mais disperse d’autant les efforts.
En revanche, pour un Etat limité dans ses moyens, les lois d’échelle restreignent les options : toute organisation qui voudrait prétendre à une IA de classe mondiale aura besoin d’environ autant de compute qu’un des leader américains, ce qui nécessite directement plusieurs gigawatt, donc des centaines de milliards d’euros. Cela exclut d’emblée que la France, seule ou même en coalition, puisse financer d’un coup plusieurs champions. Cet investissement devra donc être focalisé sur un seul véhicule.
Il s’agira alors de choisir entre deux voies : s’appuyer sur un laboratoire existant, Mistral apparaissant naturellement comme le seul candidat européen crédible, ou créer un véhicule entièrement nouveau. La première option ferait de Mistral le point d’ancrage du projet, en lui faisant absorber tous les moyens mis à disposition du projet Prométhée. La seconde consisterait à créer une structure dédiée, éventuellement à racheter les chercheurs et actifs de Mistral, si cette forme permettait une exécution plus rapide, une gouvernance plus resserrée ou une meilleure adéquation avec les objectifs du programme. Mistral est aujourd’hui valorisé à environ vingt milliards d’euros, ce qui ne représenterait qu’un cinquième du coût annuel du présent projet.
Vient la question du rôle de l'État. Deux conditions se dégagent clairement. La première est que le projet ne réussira jamais sans un engagement massif de la puissance publique, financier d'abord, mais aussi politique, diplomatique et réglementaire. La seconde est que l'État n'apporte aucune valeur ajoutée à la conduite du laboratoire lui-même, et qu'il y serait même nuisible. La difficulté est qu'il serait difficile de défendre politiquement un financement de cette ampleur sans aucun droit de regard public.
Le cœur du montage consiste donc à scinder le projet en deux. D'un côté, le laboratoire proprement dit : les chercheurs avec leur propre culture, libres de leurs choix scientifiques, entièrement consacrés à l'entraînement des modèles. De l'autre, tout le reste, c'est-à-dire en réalité un immense projet d'infrastructure ; c’est quelque chose que l'État sait mener.
À la tête de la partie publique, une direction de programme étatique assurerait la maîtrise d'ouvrage pour le compte de l'État. Son rôle serait entièrement tourné vers la facilitation du projet : accélération des procédures administratives et mise en place des régimes dérogatoires indispensables. Une “loi Prométhée” équivalente à la "loi Notre-Dame" devrait être adoptée en matière de foncier, de raccordement électrique, d'environnement et de droit du travail.
Le laboratoire prendrait la forme d'une société dont la mission unique est de déployer des modèles de frontière, sans aucune interférence dans sa gestion. L'État y détiendrait une part minoritaire significative, de l'ordre de 25 %, le reste demeurant majoritairement privé. L'idéal serait de multiplier les participations de fonds et de grands groupes industriels européens : pour ces derniers, non pas tant pour leurs capitaux que pour leur intérêt direct à disposer d'un modèle de frontière souverain et non débranchable. Les fondateurs et dirigeants du laboratoire n'auraient pas vocation à être forcément français ; il suffit qu'ils soient de première classe et qu'ils aient l'expérience de l'entraînement des modèles de frontière. En revanche, l'État serait le garant du contrôle national, avec des instruments classiques du droit des sociétés : action spécifique, droits de veto sur les changements de contrôle, clauses de localisation du siège et de non-délocalisation des actifs critiques, garantie de non-débranchabilité du modèle, etc.
Le calcul, lui, serait logé dans des structures distinctes, filiales ou joint ventures dédiées, qui auraient pour seul objet de livrer au laboratoire la puissance prévue. Elles réuniraient des investisseurs privés de toutes origines et des investisseurs publics des pays volontaires, avec une rémunération calibrée pour être franchement attractive : comme ces véhicules sont gourmands en capital, le rendement offert doit être à la hauteur pour drainer l'argent nécessaire.
Les précédents existent. L'américain Poolside a séparé son laboratoire de sa société d'infrastructure, dont la direction réunit des profils ayant dix à vingt ans d'expérience dans la construction et l'exploitation de data centers chez les grands acteurs du cloud. Mistral structure son accès au calcul par des coentreprises avec la BPI, MGX ou Nvidia.
Une dernière structure publique, distincte, aurait pour mission de mettre le nouveau nucléaire « sous stéroïdes » afin que l'énergie ne devienne pas le goulet d'étranglement de l'après-2030. Ce n'est pas l'objet de cette note que de développer cette dimension, mais elle n'en est pas moins essentielle.
Quelle coalition pour l’entreprendre ?
Dans ce genre de projets, un réflexe récurrent est de partir d’une logique européenne sans en démontrer la nécessité. Cela mène trop souvent à la recherche d’un retour géographique immédiat (comme dans le spatial ou la défense), donc à la fragmentation de l’effort et, in fine, à un échec à passer à l’échelle. C’est pourquoi nous partons des capacités françaises, la France étant la mieux placée pour initier un tel effort, d’autres pays pouvant s’y joindre en fonction des besoins et de leurs intérêts.
L’enjeu est de concentrer l’exécution et d’atteindre une vitesse de décision incompatible avec une répartition strictement proportionnelle des retombées. Les autres pays participants en bénéficieraient par des droits d’accès au compute, des crédits d’usage pour leurs chercheurs et entreprises, des marchés communs, des standards partagés et l’intégration progressive de leurs industriels dans la chaîne de valeur.
Quels pays ?
Analyse comparée des coûts et bénéfices de chaque pays participant
Les quatre premières années
Comment se déroulerait en pratique la conduite du projet ? Nous proposons le calendrier suivant pour ses quatre premières années.
Créer le véhicule avec ses différentes structures, nommer une direction exécutive et scientifique, voter la loi Prométhée
Ces prévisions s’appuient sur les durées observées dans les grands laboratoires les plus récents :
Oppositions
L’une des grandes difficultés serait, outre de mener à bien la partie administrative de ce sprint, de sécuriser l’approvisionnement en GPU. La construction des datacenters eux-mêmes, la structuration juridique du projet, les dérogations réglementaires sont à notre main ; l’accès aux puces ne l’est pas. Aucun laboratoire n’entraîne aujourd’hui de modèles sans puces Nvidia, à l’exception de Google, qui repose sur ses propres Tensor Processing Units, construits expressément pour ses besoins internes. Même les modèles chinois récents sont entraînés sur des GPU produits par Nvidia. A court terme, et tant que d’autres acteurs ne concurrencent pas ce quasi monopole, notre projet serait donc dépendant de Nvidia, c’est-à-dire de l’administration américaine. Rien n’empêcherait en effet cette dernière d’imposer des contrôles à l’export des produits Nvidia vers la France (certains pays européens en ont déjà subi), et il est possible qu’elle soit tentée de le faire en voyant surgir un effort concurrent de cette taille.
Deux solutions s’offrent alors à nous. Soit nous tentons malgré tout d’acquérir des puces Nvidia en pariant sur le fait qu’un tel marché serait trop juteux pour l’entreprise, qui jouerait de son influence à Washington pour éviter des restrictions d’exportation ; dans le pire des cas, nous devrions convaincre les Pays-Bas de menacer Nvidia et le gouvernement américain de rétorsion par l’arrêt de l’exportation des machines de photolithographie d’ASML, indispensables à la production de GPU. Il y a là beaucoup d’incertitudes. Soit nous cherchons à bénéficier de nouveaux producteurs ailleurs dans le monde. Mais il est difficile d’en trouver qui ne soient pas eux-mêmes tenus par les Américains, de manière plus ou moins directe, tout en ayant la surface requise. Même les puces de Huawei (Ascend) ne sont pas suffisantes pour la consommation des laboratoires chinois. Peut-être la situation changera-t-elle bientôt ; la Corée du Sud a par exemple annoncé un plan d’investissements de plus de 1 000 milliards d’euros pour des usines de semi-conducteurs. Mais en l’état, c’est l’un des blocages les plus solides de ce projet.
A compléter